时序巡检适用范围
从业务维度看
- 网站访问流量、延时、PV
- 产品的活跃用户数
- 业务较为稳定的机器的CPU利用率、内存使用情况、系统负载指标
- 云上SLB中的出入网流量
- K8S中Ingress访问日志的流量、延时情况
从指标形态维度看
- 具有一定业务规律的时序曲线
从指标异常维度看
- 关注指标中的突变(突刺)
- 关注指标中的漂移
- 关注指标中的局部扰动
- 关注指标中的形态改变(变点:某个观测维度上的统计指标发生了变化)
- 关注指标中的局部数据缺失、断流
典型场景:访问日志类型
对于 OSS 访问日志、Nginx访问日志、Apache访问日志、IIS访问日志来说,是重要的衡量业务整体稳定性的重要观测数据,那么如何通过访问日志来进行监控告警呢?借助《Google:Site Reliability Engineering》(具体SRE的解释参考如下引用)提供的手段我们需要对整体的访问行为进行度量。
SRE is what you get when you treat operations as if it’s a software problem. Our mission is to protect, provide for, and progress the software and systems behind all of Google’s public services — Google Search, Ads, Gmail, Android, YouTube, and App Engine, to name just a few — with an ever-watchful eye on their availability, latency, performance, and capacity.
问题回顾
通过访问日志,我们可以获取到如下基础指标:
- 每分钟访问的次数(PV)
- 每分钟成功请求的次数(200请求的PV)
- 每分钟失败请求的次数(非200请求的PV)
- 每分钟严重异常请求的次数(5XX请求的PV)
- 每分钟平均请求的延时、每分钟请求的延时的分位数大小
- 每分钟不同请求的访问次数、成功访问次数、异常访问次数
- 每分钟不同请求的平均访问延时、请求延时的分位数大小
- 每分钟、每个域名、每个请求方法在请求次数和延时上的指标
- 其它相关指标。。。。。。
面对上面的多维度的指标,我们先来使用生动形象的图标来刻画一下目前的配置现状,通过自己维度一堆执行脚本(SQL查询)和各自规则的阈值来实现对于上述指标的检测。关于规则的阈值,往往是需要反复的调整,且需要按照时间(节假日、工作日、白天、晚间等)进行调整。
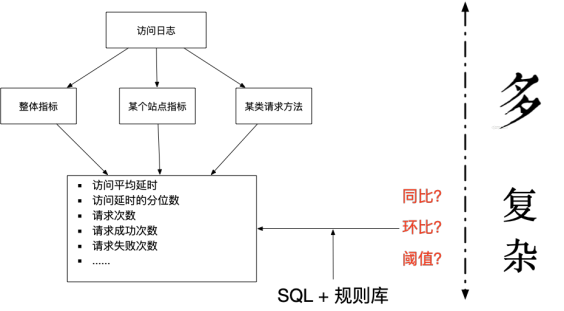
针对以上问题,我们可以通过以下SQL来完成观测指标的智能检测。
解决方案
这里我们按照访问日志为例子进行配置的拆解:
- 数据已经存储在SLS中,并且相关字段已经配置好索引
- 数据已经存储在SLS中,并且存储超过1天以上(数据的可观测时间长度在2周左右最好,大部分业务数据是按照周有一定的规律的)
1. 对全部域名进行指标监控
在这个场景中,需要关注网站的核心PV情况,已经延时的均值和分位数情况:
*|select __time__ - __time__ %60astime,'all_domain_instance'as target,COUNT(*)as total, count_if(request_status ='200')as succ, count_if(request_status !='200')as fail, count_if(request_status like'50%')as fata, avg(response)*1000as response_avg, approx_percentile(response,0.95)*1000as response_p95 from log groupbytime, target orderbytimelimit100000
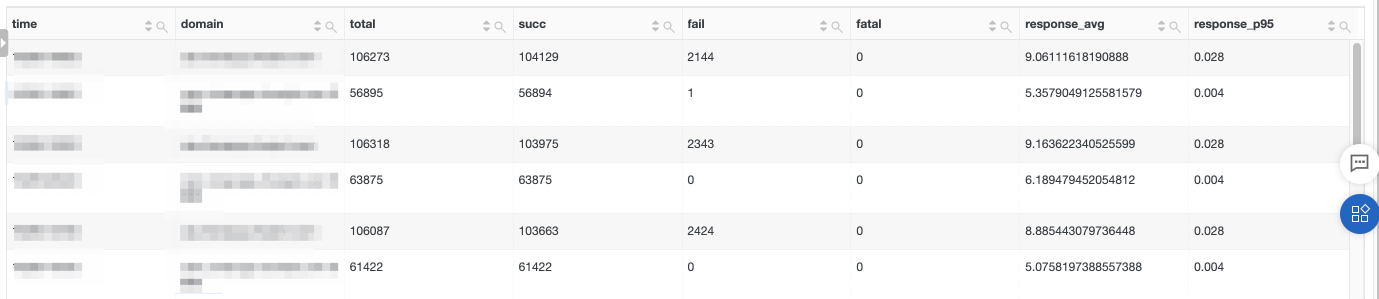
这里我们拿到了如下结果,说明下对应字段的含义和使用的注意事项:
- time : 在时序巡检中,需要有一个维度是表明时间信息的;
- target : 在时序巡检中,至少要包含一个巡检实体,方便后续的告警、查询、可视化等操作,在这里我们使用"all_domain_instance"作为我们的观测实体对象;
- 实体对象的观测特征:[total, succ, fail, fata, response_avg, responce_p95],需要注意的是,在巡检特征中,提供的设计时间维度的指标最好按照毫秒来表示,这样算法学习的会更加准确;
- 在SQL语句的左右,一定要添加上 limit 1000000 这部分;
2. 对核心域名的指标进行监控
上部分仅仅解决了宏观层面指标的提取问题,那么写下来,我们一起来生成下关于某个核心域名的指标监控问题,所涉及到的数据如上面的数据格式说明所示,具体指标提取函数如下:
domain:'a.b.c'or domain:'d.e.f\:8888'|select __time__ - __time__ %60astime, domain,COUNT(*)as total, count_if(request_status ='200')as succ, count_if(request_status !='200')as fail, count_if(request_status like'50%')as fatal, avg( case when response isnull then 0.0 else response end )*1000as response_avg, approx_percentile(case when response isnull then 0.0 else response end,0.95)*1000as response_p95 from log groupbytime, domain limit1000000
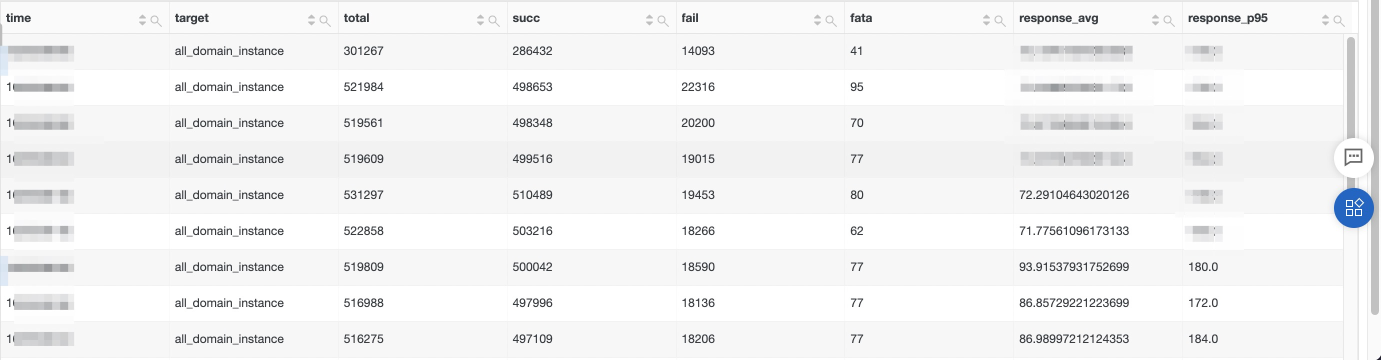
这里我们拿到了如下结果,说明下对应字段的含义和使用的注意事项:
- time : 在时序巡检中,需要有一个维度是表明时间信息的;
- domain : 在时序巡检中,至少要包含一个巡检实体,方便后续的告警、查询、可视化等操作,在这里我们使用每个访问的域名作为我们的观测实体对象;
- 实体对象的观测特征:[total, succ, fail, fata, response_avg, responce_p95],需要注意的是,在巡检特征中,提供的设计时间维度的指标最好按照毫秒来表示,这样算法学习的会更加准确;
- 在SQL语句的左右,一定要添加上 limit 1000000 这部分;
PS:在SLS平台中,查询语句前面可以进行快速的过滤,最多可以开放三十个关键词的查询,如果遇到较多的域名需要进行查询,可以在文章下面留言,下一期提供大量过滤条件下的最佳配置实践。
通过上述步骤1和步骤2,我们完成了基于访问日志的指标的提取,接下来就是进入到快速配置巡检的阶段!
3. 时序巡检配置步骤
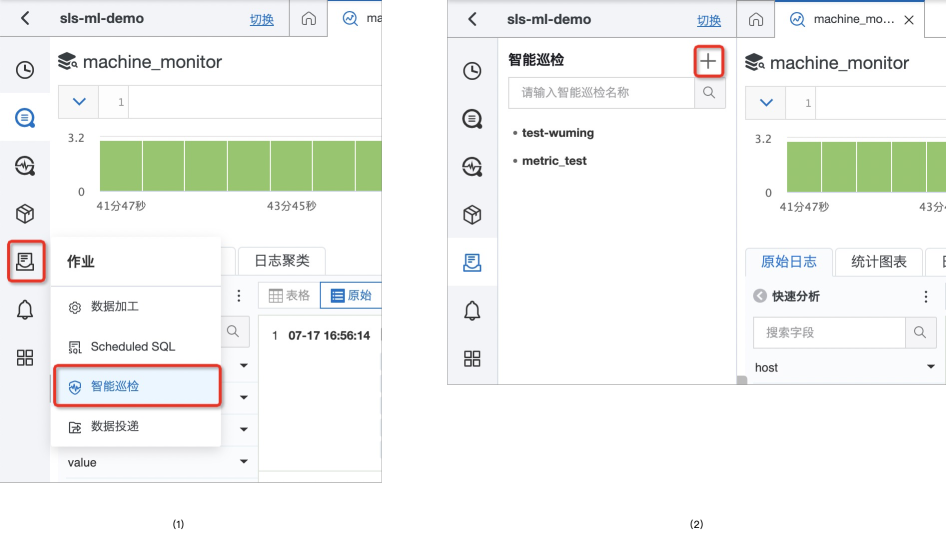
- 找到巡检配置在SLS的访问入口
- 在SLS的控制台中,进入需要巡检数据的Project/LogStore
- 在左侧的边框导航栏中,可以通过如下截图中的步骤,找到 【智能巡检】的入口
- 根据图(2)提供的标记,找到作业创建的入口
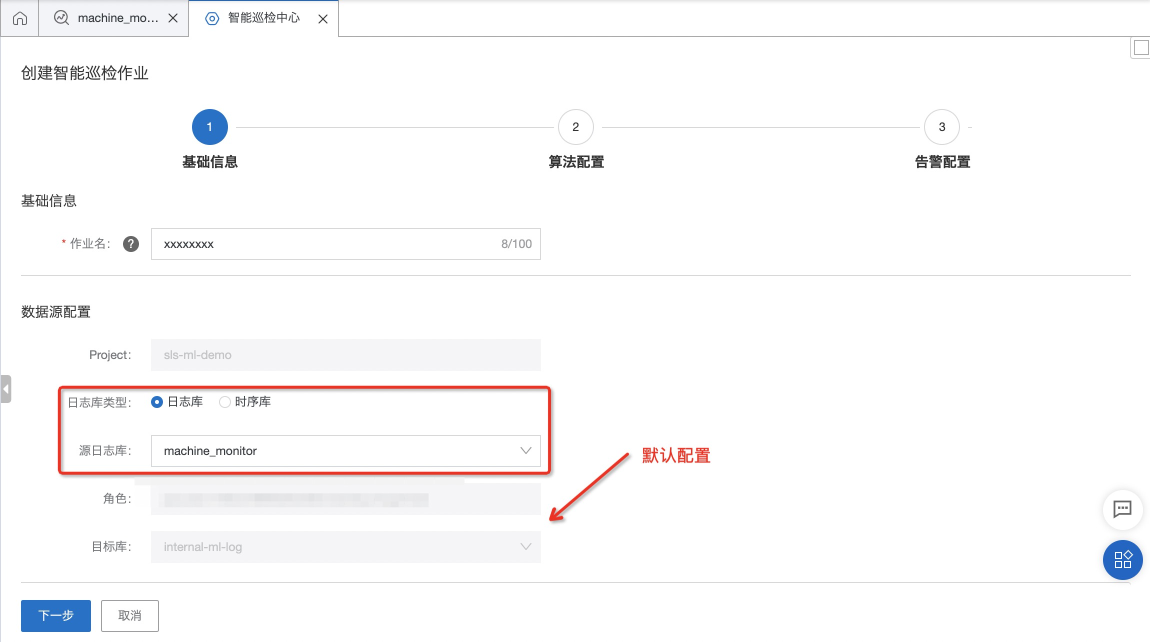
- 完成基础数据源的选择,还有相关权限的授予
- 按照规范完成作业名的填写
- 配置好对应的数据源(待巡检对象的数据存储的位置)
- 【默认配置】:这里是关于权限的配置,具体的可以参考文末链接,同时我们会将结果创建存储巡检结果的logstore - internal-ml-log,关于该logstore的说明,可以文末链接
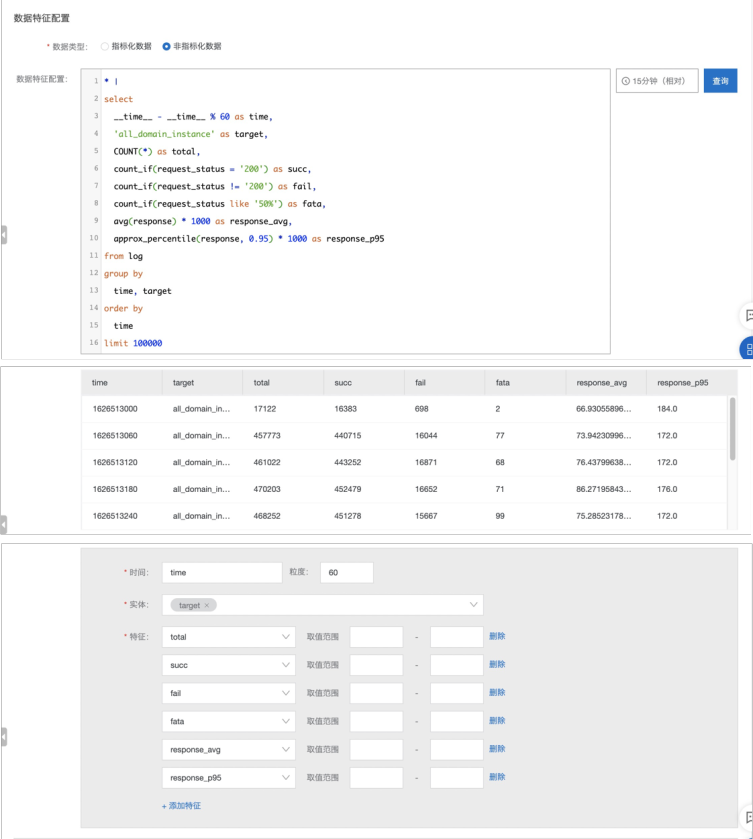
- 进入到巡检作业的主体配置页面【数据特征配置】
- 数据类型:选择【非指标化数据】,咱们是通过【原始的访问日志】通过SQL的操作生成待观测的指标,点击【查询】后会返回对应的表格结果
- 针对数据样例,填充对应的配置
- 【时间列】:根据结果选择 "time" 这个字段,因为咱们的SQL是通过 "__time__ - __time__ % 60 as time" 进行聚合的,因此我们的时序是按照【分钟粒度】进行统计的,所以【粒度】这里填充 60 单位是秒
- 【实体】:就是我们的观测对象,在当前的Query结果中是来监控全局的各种指标的,因此选择 "target" 这个字段来表示实体维度
- 【特征】:选择查询结果中的数值列(bigint、double类型的数据)作为我们观测对象的监控维度;
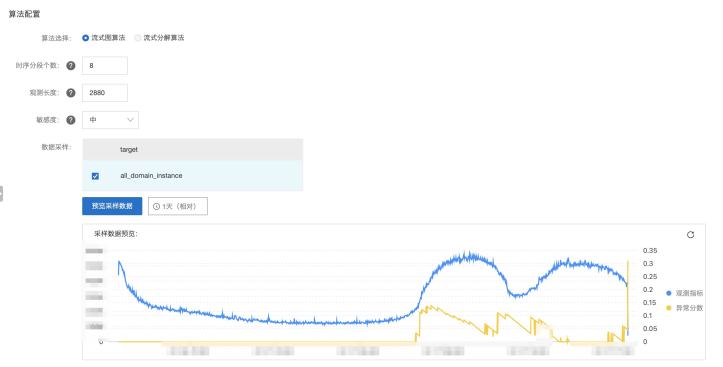
- 【算法参数】配置部分
- 目前我们提供了一个稳定的算法:流式图算法
- 对应的算法参数可以详见我们的官方文档
- 预览采样数据:我们会按照您提供的SQL去获取指定时间长度的数据,完成算法的预览,便于您去调整算法的效果
- 关于检测结果的异常分数可以详见参考文档
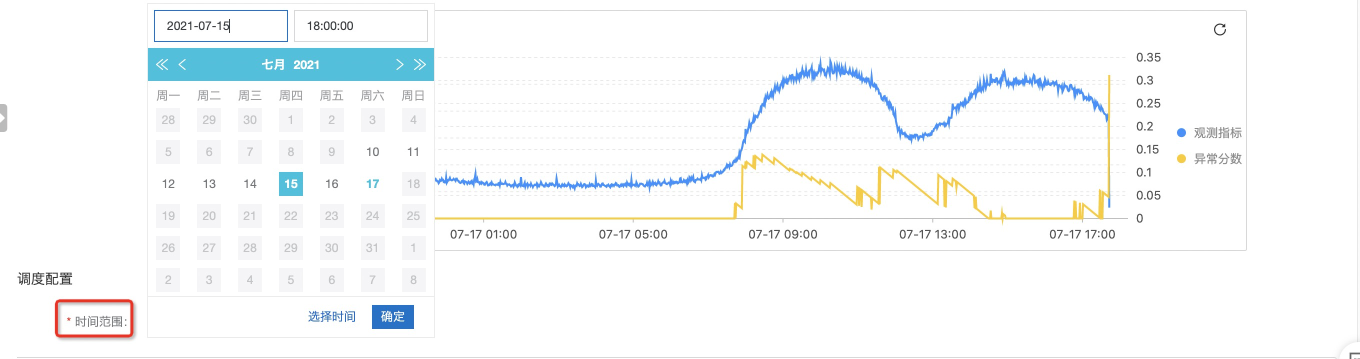
- 【调度配置】部分
- 这里是当前的巡检任务开始获取数据的时间点
- 如果您的数据保存的时间比较长,建议从当前时间计算开始2天前的时间点;
- 如果您的数据保存的时间比较短,建议从当前时间计算开始12小时前的时间点;
- 需要说明的一点是:巡检作业会从指定的时间开始,顺序读取数据,当作业追到当前的提交的时间点后,会逐步输出巡检解决,具体的进度可以在 internal-ml-log 中进行查询
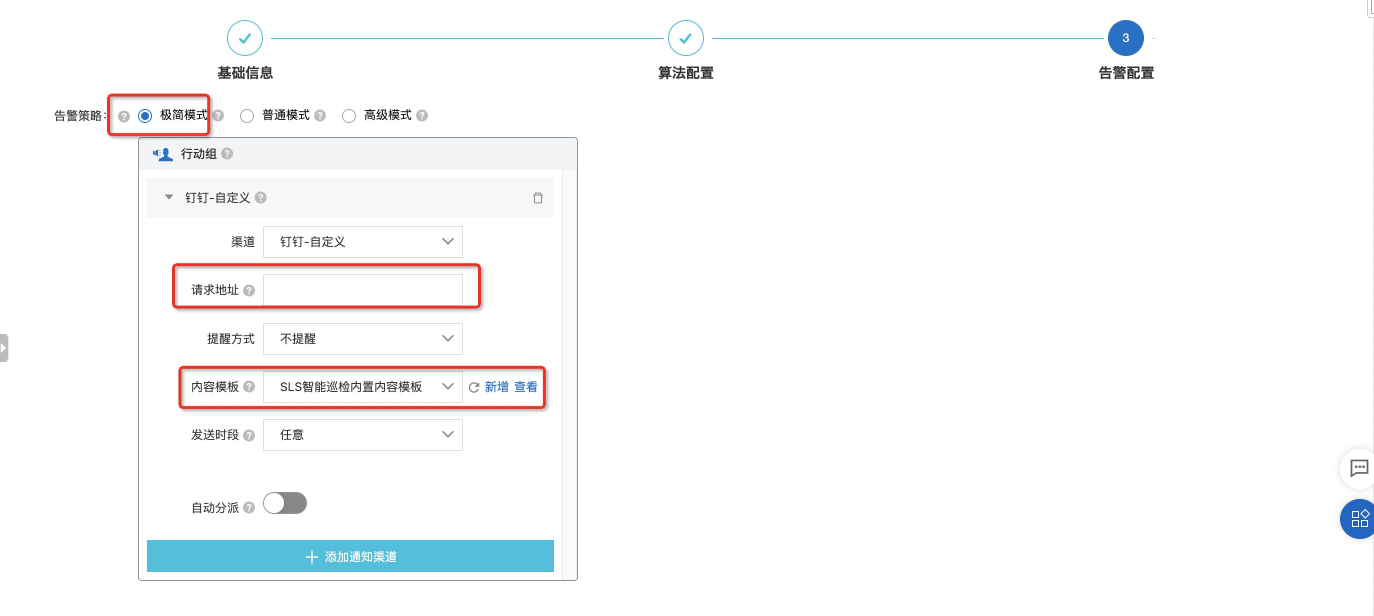
- 【告警配置】部分
SLS平台会内置提供【行动策略】和【内容模板】,具体的配置内容可在【告警中心】中进行查看。
默认的行动策略:SLS 智能巡检内置行动策略 - sls.app.ml.builtin
默认的内容模板:SLS智能巡检内置内容模板 - sls.app.ml.anomaly.cn
- 【极简模式】: 默认指定的是告警策略是【极简模式】,在该模式下,默认提供的是【钉钉-自定义】的通知渠道,您只需要将自己的钉钉机器人填写到【请求地址】中就可以的。默认的【内容模板】是我们提供的【SLS智能巡检内置内容模板】
- PS:当完成该操作时,会在【告警中心】【行动策略】中自动创建一个以 "alert.simple."开头的行动策略,后续的渠道的需求,无需去修改巡检作业的配置,只需要在【告警中心】修改对应的通知渠道就可以了
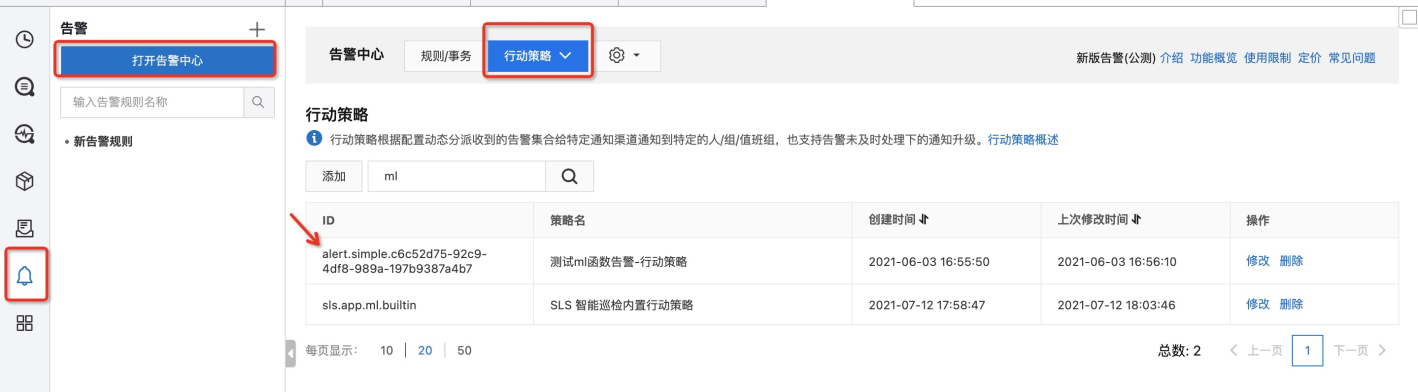
- 【普通模式】和【高级模式】您可以直接去管理自己的【告警策略】和【行动策略】


4. 时序巡检的告警显示
- 如果有任务巡检的告警结果,会通过【您配置的钉钉机器人渠道】发送出去,具体的形式如下,您可以通过点击【误报】和【确定】跟SLS的系统进行交互,目前点击后会【弹出空白的钉钉侧边栏】这个目前不影响您使用
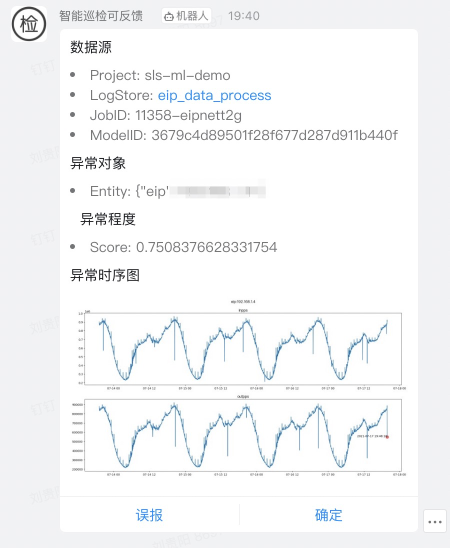
- 您可以通过查询巡检大盘来看历史上某个作业中观测对象的告警历史,具体的地址在如下位置:
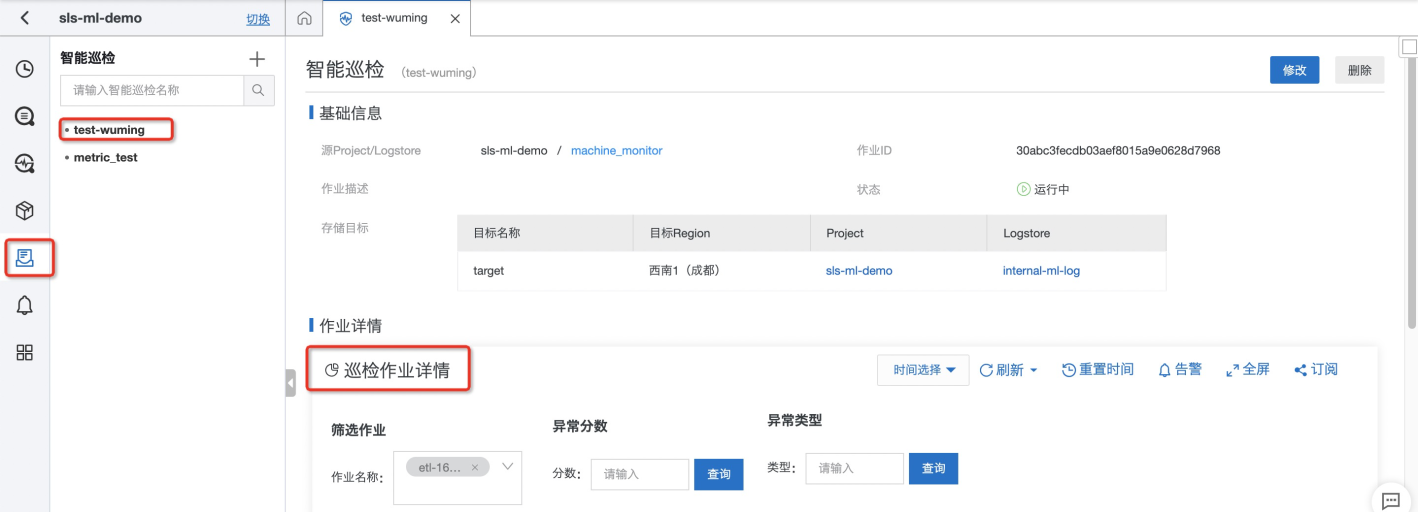
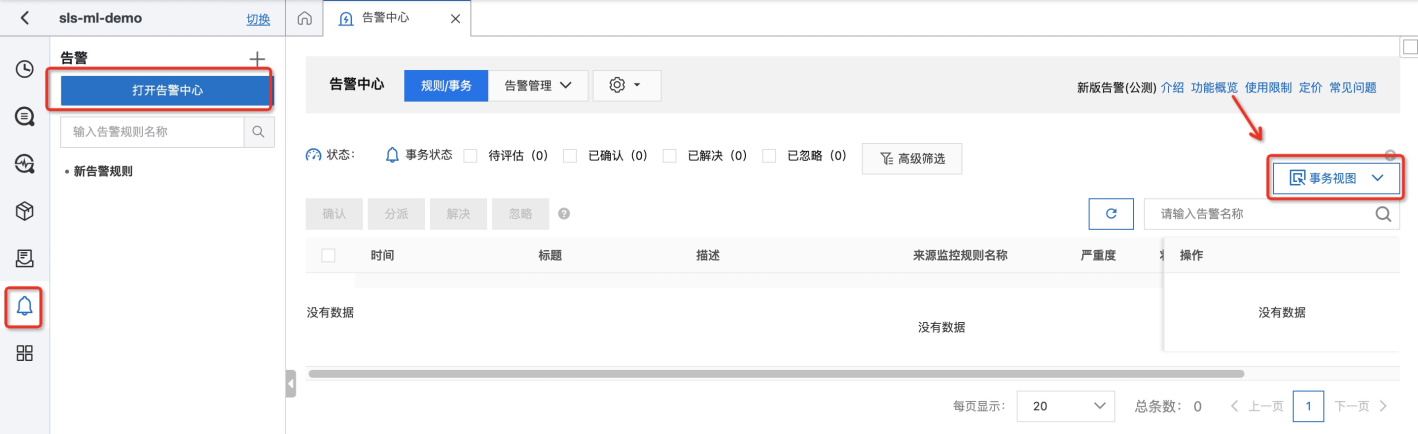
- 当然,您也可以通过告警系统来查看所有的告警历史记录
参考文档
- AIOps 自适应机器学习异常检测 https://zhuanlan.zhihu.com/p/377837205
- 智能巡检概述 https://help.aliyun.com/document_detail/253411.html
- 查看巡检结果 https://help.aliyun.com/document_detail/275370.html
- 打标反馈 https://help.aliyun.com/document_detail/275225.html